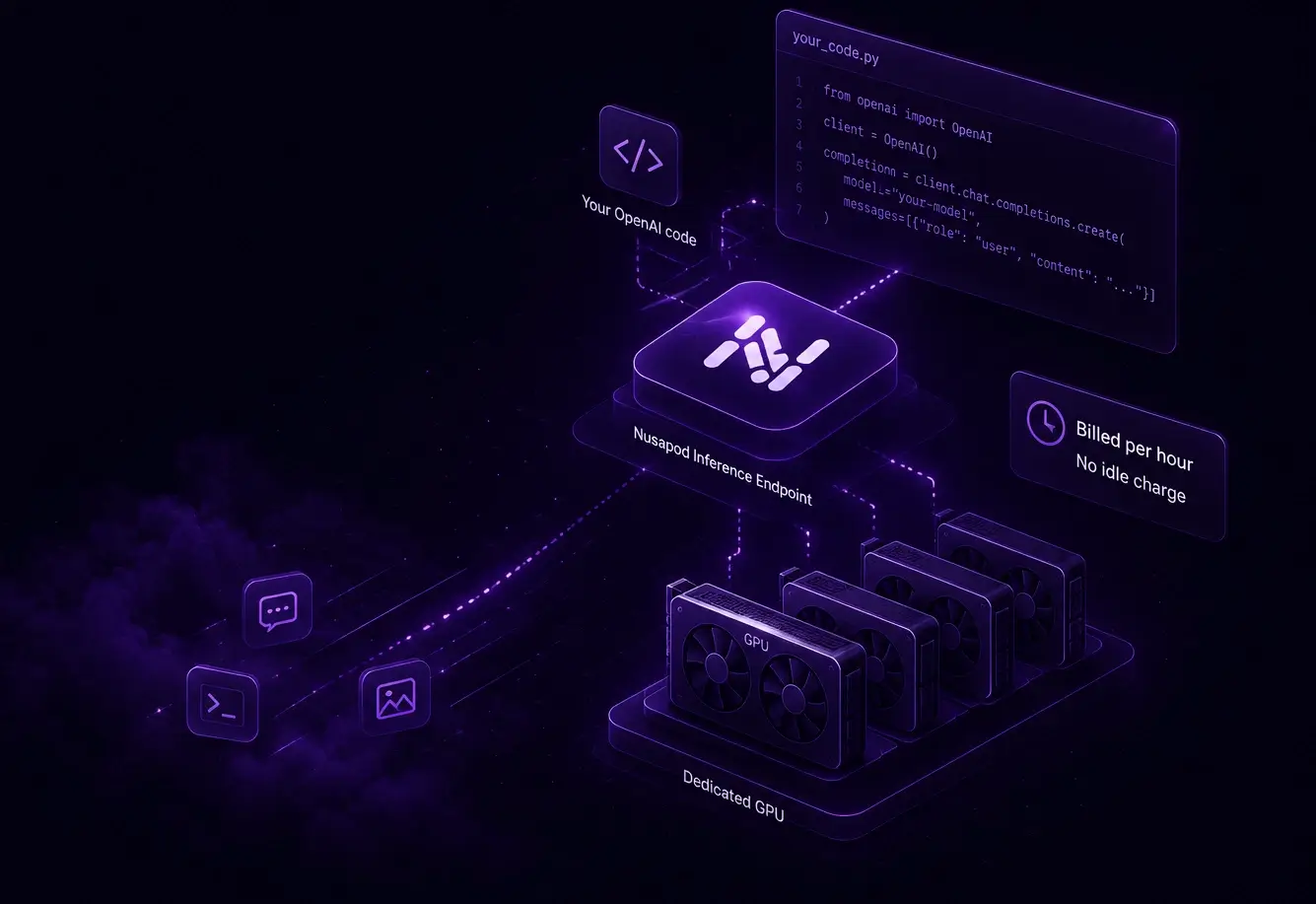
Drop-in OpenAI API
Keep your OpenAI client and request shape. Swap the base URL and key, and your existing code talks to your model.
Keep your OpenAI client and request shape. Swap the base URL and key, and your existing code talks to your model.
Requests run on a dedicated GPU you control, so behaviour and latency are predictable instead of shared and noisy.
You rent the GPU by the hour; the throughput it produces is yours. There is no per-token bill to forecast.
The familiar chat completions endpoint, served from your deployment. Streaming and standard parameters work as you expect.
Create and revoke keys from the dashboard. Scope access to your endpoint without touching infrastructure.
Stream your deployment logs in real time to watch boot, requests, and errors as they happen.
Billing tracks the GPU, not the request. Stop the deployment and the meter stops — no per-call accounting.
Back a conversational product with a stable, OpenAI-compatible endpoint.
Use the chat completions API as the generation step in a retrieval-augmented stack.
Drive tool-using agents against an endpoint you control, at predictable per-hour cost.
Add inference to internal apps without standing up your own serving infrastructure.
Yes. Your deployment exposes an OpenAI-compatible API, including /v1/chat/completions. Existing OpenAI client code works by changing the base URL and key.
No. To be plain: "serverless" here means you do not manage the server — but billing is per-hour GPU rental, not per request or per token. You rent the GPU; the throughput is yours.
Create and revoke API keys from the dashboard, then pass one as the bearer token your OpenAI client already sends. Revoking a key cuts off access immediately.
Yes. Deployment logs stream live over SSE, so you can watch boot, requests, and errors in real time from the dashboard.
Open models from the catalog — Qwen, DeepSeek, Llama, Gemma and more — or your own weights or container. They run on vLLM behind the endpoint.